I. A Data Stream System for Uncertain Data Management
Uncertain data streams, where data is incomplete, imprecise, and even misleading, have been observed in a variety of environments. In many cases, the raw data collected is not directed queriable and hence, needs to undergo sophisticated query processing to derive useful high-level information. Also, feeding uncertain data streams directly to existing stream systems can produce results of unknown quality. The goal of this project is to design and develop a stream processing system that captures data uncertainty from data collection to query processing to final result generation. This project takes a principled approach grounded in probability and statistical theory to support uncertainty as a first-class citizen, and efficiently integrate this approach into high-volume stream processing.
- System Architecture:
As stated in the project overview, the CLARO system involves two processes: data capturing and transformation and relational processing under uncertainty. The below figure shows the architecture overview of CLARO, an uncertainty-aware stream system. The T operators transform raw data streams into queriable data streams with quantified uncertainty. The A and T operators are examples of relational operators, i.e., aggregates and joins respectively. These operators manipulate and process data modelled by continuous random variables. The final results can be characterized by confidence regions or other statistics such as mean and variance values.
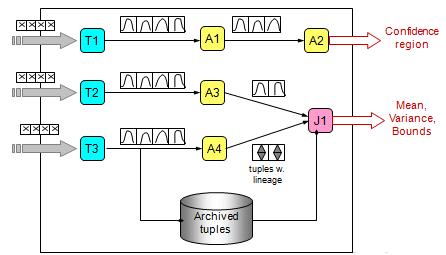
- Data Capturing and Transformation:
Since the raw streams may not present data in a format suitable for query processing and can be highly noisy, this project employs probabilistic models of the underlying data generation process and machine learning techniques to efficiently transform raw data into a desired representation with an uncertainty metric. The following figure shows a graphical model built for the RFID application.
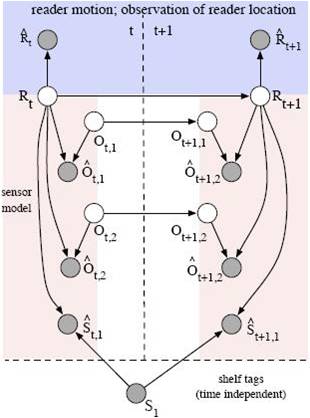
- Relational Processing under Uncertainty:
To efficiently quantify result uncertainty of a query operator, CLARO explores various techniques based on probability and statistical theory to reduce statistics that data streams need to carry and to expedite the computation of result distributions using approximation. Examples of techniques applied are characteristic functions and regressions..
- Probabilistic Threshold Query Optimization:
Given input data with uncertainty, users would want to retrieve query answers of high confidence, reflected by high existence probabilities of these answer. Probabilistic threshold queries return tuples whose existence probabilities pass the user-specified threshold. We optimize threshold query processing for continuous uncertain data by (i) expediting selections by reducing dimensionality of integration and using fast filters, (ii) expediting joins using new indexes on uncertain data, and (iii) optimizing a query plan using a dynamic, per-tuple based approach.
II. Supporting Uncertain Data in Array Databases
Uncertain data management has become crucial to scientific applications. Recently, array databases have gained popularity for scientific data processing due to performance benefits. We address uncertain data management in array databases, which may involve both value uncertainty within individual tuples and position uncertainty regarding where a tuple should belong in an array given uncertain dimension attributes. Our work defines the formal semantics of array operations under both value and position uncertainty. To address the new challenge raised by position uncertainty, we propose a suite of storage and evaluation strategies for array operations, with a focus on a new scheme that bounds the overhead of querying by strategically treating tuples with large variances via replication in storage.
Last Update: August 2016